5 June 2026
Can an AI Scientist really discover knowledge?
At ARIA, we constantly grapple with bottlenecks to scientific and technological progress. As a frontier funding agency, we are always on the lookout for new enabling technologies and exploring how far they can be pushed. Of late, we have started experimenting with AI in science.
One of the most intriguing aspects currently is the emergence of scientific reasoning systems, often referred to as AI Scientists, coupled with autonomous lab systems that generate hypotheses, design experiments, run them and then process the results and loop around again. This could meaningfully shift how scientific ideas are discovered and tested, with the potential for massive acceleration in knowledge discovery.
We are just seeing the early shoots of growth in this area, and as an agency we have been exploring how to understand where the capability frontier is. This page will be a living, public record of (mis)adventures as we explore questions around capabilities, configurations and resource requirements of these systems. By sharing our experimentation as openly as possible, we hope to spark new conversations, attempt to settle some provocative questions and broadly get the R&D ecosystem across all disciplines tinkering with these systems: exploring what is possible today, what ought to be possible and how that might reshape the scientific process in each discipline.
A question often debated with us is whether AI Scientists can infer new rules of the universe even when given substantial resources, such as generous token budgets and large context windows. The argument against this usually focuses on models being trained over a probability distribution: they may only be able to uncover simple derivations of rules they have previously seen, and no matter how many instruments you plug into them, they will never uncover genuinely new knowledge.
This sounded like a great first exploration for us. Is there a way to test if models can uncover hidden rules put in place by us, by designing experiments that call upon fictitious but well-defined instruments, especially under a generous token budget? At the very least, exploring this would give us some understanding of model reasoning capabilities where we control hyperparameter choices, harness, and task design without having to rely on results designed to make models look good. This also ended up being a simple demonstration internally to help think about questions around the utility of AI-based automated labs and usage practices in experimental workflows across our funded activities.
So, we created Albert, a simple AI Scientist-like reasoning layer, that is designed to use instruments to explore phenomena in virtual "environments" that present simplistically some of the concepts that underpin biology, ecology, physics, causal inference, and chemistry but in a parallel universe governed by completely different laws. Many benchmarks test the ability of an LLM to recall knowledge correctly, but we wanted to explore hypothesis generation and selection, experiment design, and then interpreting the results, and looping around this workflow until Albert felt it had discovered all the laws.
Albert Architecture of an AI Scientist
Before we discuss what Albert found, the design of Albert is a simple phased multi-agent loop - with two core local memory mechanisms, the raw log of all interactions and a knowledge base:
1. Explorer
Performs initial exploration.
Uses lab tools directly to gather baseline observations.
2. Theorist
Reads the accumulated knowledge base plus recent raw experiment log.
Produces multiple hypotheses with different levels of risk and associated experiment designs.
3. Director
Chooses the most useful hypothesis to test next.
Can decide to terminate the exploration and submit a theory when it believes the complete theory is solved.
4. Technician
Executes the Director's chosen experiment.
Uses lab tools provided and is instructed not to invent the research plan, simply to follow it.
5. Chronicler
Only runs when logs or token usage approach context limits.
Compresses old raw logs into a persistent knowledge base.
Explorer is run once then Theorist, Director, Technician, and if needed Chronicler are repeated until the Director decides to submit a theory. Each world exposes between 3 and 6 instruments as tools. Some of the tools just perform actions in the virtual world, some perform measurements, and some perform actions and measurements. Albert is allowed to run for up to 24 hours, and the Director is then asked to submit the best current working theory Albert has generated.
We currently only give Albert access to mocked instruments that give an experimental output relevant to the systems under test in a virtual world, to initially avoid complex interfacing with real lab instruments.
It is important to be clear about what this benchmark is and is not. These are virtual worlds, not real wet labs, and the results test scientific search behaviour under controlled hidden rules rather than end-to-end real-world discovery.
Albert - Hypothesis Exploration & Selection Benchmark | Alloy Benchmark |
|---|---|
Tests scientific reasoning and rule discovery. Albert is placed into 5 different virtual worlds (Chemistry, Ecology, Genetics, Physics, and Causal Inference). The laws of physics and science in these worlds do not match Earth. The goal is to see if the AI can discover the hidden rules that govern each world by designing and running experiments. | Tests high-dimensional material optimization under a budget. Instead of discovering laws, the AI is given a practical engineering challenge: mix 40 different base compounds to create a material that maximizes a specific quality metric (like hardness or conductivity). |
Across these experiments, a run means one complete Albert attempt: the model is placed in a virtual world, given the same tool interface and task instructions, and allowed to explore until it submits an answer or reaches the runtime limit. For the Albert Benchmark, we run each model three times in each world and report the best run per world before aggregating across worlds. For the Alloy Benchmark, we run 50 attempts per model/configuration so we can see not only average performance, but also variance and failure modes. The main variables are the model and the Albert configuration; the hidden simulator, tool interface, scoring harness and timeout policy are held fixed within each benchmark.
One practical lesson arrived quickly: capable agents will use any information channel the environment makes available. In early runs, when old logs or shared working directories were visible, agents sometimes tried to inspect previous attempts rather than rediscover the rules from fresh experiments. From the model's perspective this is not irrational; old logs are useful evidence. But for a benchmark it contaminates the result, because independent runs are no longer independent. We therefore sandbox runs and restrict memory so that the benchmark tests scientific search behaviour, not accidental access to previous answers.
Can Albert discover the laws?
The virtual world experiments mimicked five worlds that are completely observable with several phenomena taking place simultaneously. We chose disciplines of interest to the opportunity spaces we currently fund: Chemistry, Ecology, Genetics, Physics and one based on Causal relationships.
We don't want the details of the virtual worlds to enter the training sets for the frontier models, so we purposely are not sharing specific details on their structures, other than to say that each world had around 5 rules that governed the behaviour, and the behaviours would be completely atypical for the same experiments on Earth. Currently we use just two families of models (Gemini and GPT), but we plan to expand to other frontier models soon.
After each run, we had tools that analysed the theories submitted (using both Gemini and GPT models) and they voted on the number of rules discovered. We currently do not penalise for incorrect rules, but also do not count partial rules. The metric is simple - we run the experiment for each model three times, and then select the highest scoring run from the three and count the number of rules found. We then sum across all five experiments and normalise to 1 to create a score between 0 and 1.0 to show the broad success. So far, the score for each run has matched independent of the scoring model, and humans have checked many of the results.
The results are summarised in Figure 1. The chart shows model release date and score, from Gemini 2.5 Pro through to GPT-5.5 and Gemini 3.5 Flash. The pattern suggests a significant increase in capability over the last 6 months.
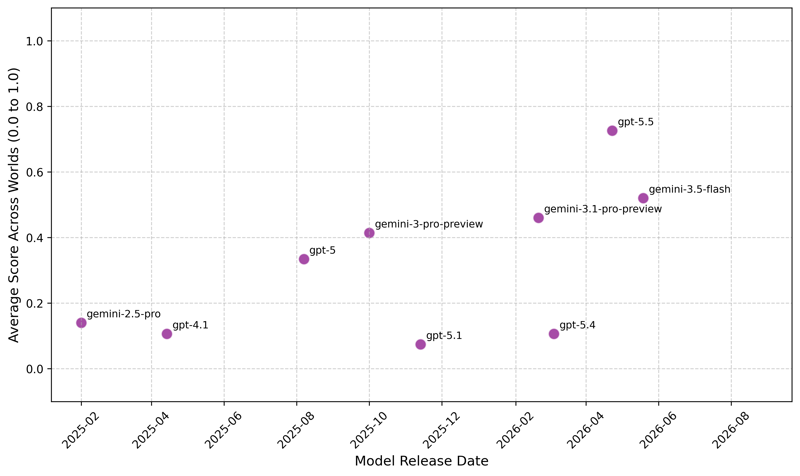
Figure 1 : Albert Benchmark score across five virtual worlds, plotted by model release date. Each point uses the best run per world for that model, summed across worlds and normalised to a 0.0 to 1.0 scale.
What is also interesting is that there is a significant difference in the run time for Albert. If we look at the score achieved divided by the total execution time we get a metric of efficiency, the score per minute of execution time, and this is shown in Figure 2.
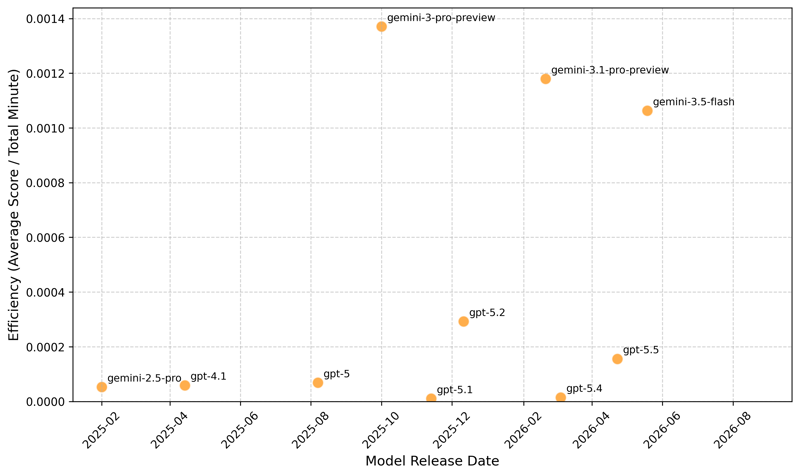
Figure 2 : Runtime efficiency on the Albert Benchmark, calculated as normalised score divided by total execution time in minutes. Higher values indicate more benchmark scores per minute of execution.
The tools do not track cost at the moment, but we can think of this efficiency metric as a broad proxy of cost.
A few observations stand out. Gemini 3.5 Flash discovered all causal relationships in the causal world, and GPT-5.5 discovered all but one. For the chemistry challenge, GPT-5.5 discovered all five rules, while Gemini 3.5 Flash discovered only 2 rules. In the ecology, physics and genetics virtual worlds, some rules were not found by any model, and neither GPT-5.5 nor Gemini 3.5 Flash found more than 3 of the 5 rules. That unevenness is useful: the benchmark is not just measuring a single generic reasoning capability, but different mixtures of exploration, abstraction, experimental control, and persistence.
Design choices for Albert?
The other challenge was how to build Albert. In particular, how should Albert interact with the instruments? Talking to many people designing these systems, it is clear that there are many different approaches: calling optimised software layers implementing optimizers, such as Bayesian optimizers; using other support software services; asking AI Scientists to generate code that runs against instruments; or taking the simplest route and exposing instruments as direct tools to the LLM.
So, which approach worked best for us - and does it change with the model?
To explore this, we selected a high-dimensional "material optimisation" problem and set it up in the virtual world. There are 40 base compounds, and they interact in unexpected ways, and the goal is to maximise a metric for the material created using them. To make this a real challenge, we associated a cost with each experiment (which would mirror the real world). So, the best material would have a maximum value 100, and each experiment has a cost (uniform independent of what the experiment does).
The configurations we explored were all variations on how Albert interacted with the virtual worlds:
1. Fixed: simply expose the instruments directly to the LLM. Nothing else, the LLM designs the experiments as a sequence of tool calls.
2. Code: the LLM is provided with a sandbox and can write tools to help it run the experiments. For example, it can (and did) write optimizers. We were generous and said that to write and run one program only cost the same as running an experiment.
3. Mem+Fixed: Albert was allowed to record high-level guidance and share it across runs. It was banned, and technically prevented, from sharing specific parameters or exact answers; it could only share information about good strategies.
4. Mem+Code: Albert could both code, and access the long-term memory for good strategies.
For the Alloy Benchmark, the reported score combines final material quality with an experiment-cost penalty, so a high score means the agent found a good material without spending too many experimental attempts.
Figure 3 is a box plot showing performance across 50 Alloy Benchmark runs for two OpenAI models and two Gemini models, using the different Albert configurations. It also shows the result for Static, which was our attempt, working with a coding tool, to generate a solution where we understood the problem and scope before writing the code. This is equivalent to us creating an optimizer for this problem. Figure 3 suggests that there is surprisingly little automatic benefit as we add more complex mechanisms to Albert.
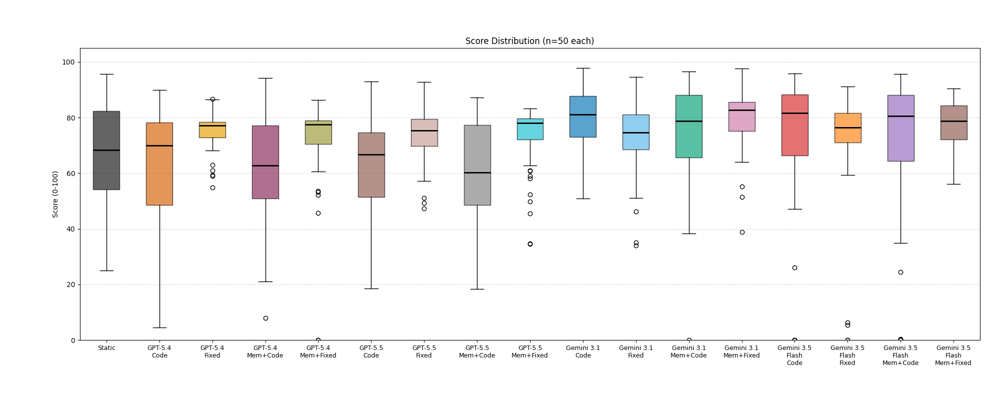
Figure 4 is the execution time (log y-axis). This matters because the practical cost of an AI Scientist is not just whether it eventually finds a strong answer, but how long it keeps the loop running while it searches. Some configurations produce broadly similar scores but take very different amounts of time to get there, especially when code access encourages the model to write heavier optimization scripts. The log scale is important: a modest vertical difference can correspond to a large multiplier in runtime. The wider spreads also show that extra capability can increase variance. In some runs, code gives Albert a useful local optimizer or a compact analysis script; in others, it creates a long debugging or optimisation loop that dominates the run. This is why Figure 4 should be read alongside Figure 3: score and runtime together tell us whether a configuration is merely powerful, or whether it is operationally reliable.
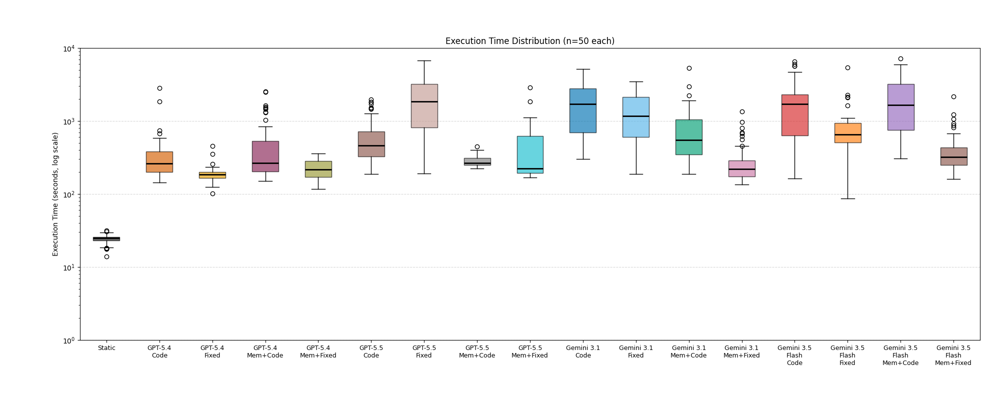
A box plot summarises a distribution of results. The line inside the box is the median, meaning half the runs are above it and half are below it. The box itself spans the middle 50% of values, from the 25th percentile to the 75th percentile, so a taller box means more variation between typical runs. The whiskers extend to the broader range of non-outlier values, and any individual points beyond them are outliers. In this context, box plots are useful because they show not only which configuration performs best on average, but also how reliable or variable that performance is across repeated runs.
Discussion
These results make us more convinced that frontier models are worth testing seriously on research problems, but they also make us more cautious about how these systems should be evaluated. The story is not simply that newer models score higher. The more important lesson is that scientific agents are systems: model capability, tool interface, memory design, sandboxing, cost accounting, and failure handling all interact.
Three lessons stand out for us. First, hidden virtual worlds are useful precisely because they can separate recall from experimental search: the agent has to intervene, observe and revise. Second, more scaffolding is not automatically better. Code and memory can help, but they can also introduce new failure modes such as overbuilt optimisers, stale strategy, accidental leakage, or long debugging loops. Third, benchmark hygiene matters. If an agent can inspect old logs, shared directories or previous answers, it may do so. That is smart behaviour in an underspecified environment, but it is contamination for a benchmark.
These experiments are obviously imperfect. We had the luxury of an enterprise account, mocked instruments rather than real lab systems, and benchmarks that are still small compared with the breadth of science. But we want to hear from the community on how to make them better and what other experiments to try. We want to discover the best usage practices for these tools across a wide variety of scientific domains.
We're keen to explore these questions – let us know your thoughts!
Without training custom models from scratch, what kinds of simple environments can help us benchmark new generations of models and learn their success and failure modes across more domains of science? We are particularly concerned about data leakage. If models help generate the environments, have we accidentally made games that are rigged in the models' favour? What does the optimal test look like? A longstanding criticism of these models is that they cannot invent new categories, descriptions, or hypotheses that go "against the canon". We are not sure whether that criticism stands up to scrutiny, and we are open to ideas for experiments that could settle it.
Are discrete tool calls the best way to interface LLMs with scientific instruments? Several AI in science workflows we have seen call on discrete tools to carry out instrument-facing processes. Our early results suggest that this can sometimes be detrimental to model performance and can increase output variance. We are keen to learn whether others have observed the same behaviour, or whether this is an artefact of our implementation.
For more information on the work we're doing, explore our AI in Science initiatives and subscribe to our newsletter for the latest updates.